The main objective of this article is to cover the most important concepts of automated learning and landscape design. The reader will have the vision to understand the type of solution that matches a particular type of problem, and must be able to find a more specific knowledge after indulging in a real project.
What is automated learning?
I will begin with the definition of 60 years, but I am still valid today:
Automated learning is the field of study that gives computers the ability to learn without being explicitly programmed.
Arthur Samuel (1959)
The name is self-explanatory and the definition reinforces the same concept.
For those who like the mathematical definition, we can relate to the 1998 definition:
It is said that the computer program learns from experiment E in relation to some tasks T and that some performance measures P, if improved in T, measured by P, experiment E.
Tom Mitchell (1998)
Let’s use a typical example to illustrate these concepts: classifying email as spam or spam. What we usually do is:
Task T is the sort of e-mail messages
Experiment (E) detects how users classify their email messages manually and describe them as spam.
Measure P is the percentage of emails that are correctly classified as spam.
We have automatic learning if P improves over time.
We have two main categories of automated learning: supervised and unmonitored learning.
Learning under supervision
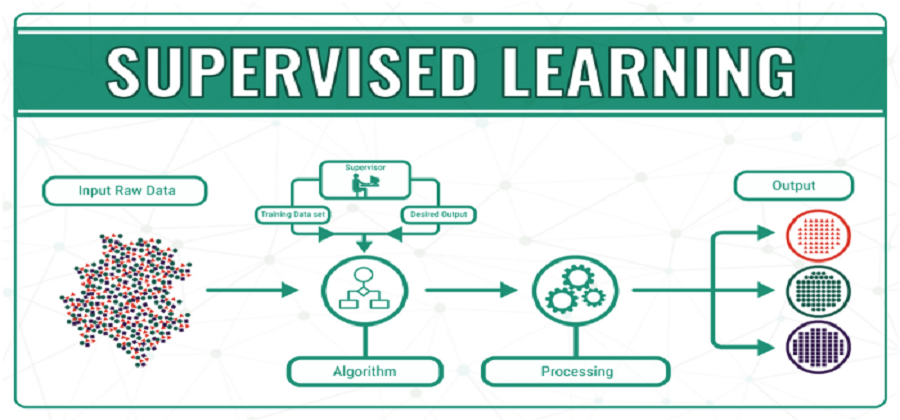
This means that we have a training group: a list of “correct values”. The main goal is to train the algorithm so that it can train its own learning mechanisms using these values to finally be able to predict unseen situations.
Some examples can be:
- Expect the price of the property based on its size and services.
- Recognize things in pictures.
- Examine the student’s degree in the exam, based on the results of previous tests.
Uncontrolled learning
It is also known as self-regulation and allows modeling the density of the probability of input given. Basically, try to discover patterns within the data.
Let’s say we have a data set and are not told about each data point. Instead, just tell us that there is a set of data here. Ask our algorithm if any structure can be found in the data.
For example, an unmanaged learning algorithm can decide that data live in two different groups.
For example, aggregation is used in Google News and if you have not already seen it, you can visit the news.google.com URL for a look. Latest Trends in Tech What Google News does is go daily and watch tens of thousands or hundreds of thousands of new stories on the web and compile them into cohesive news.
Some of the most common algorithms used in unattended learning are:
gathering
Detection of anomalies
Some types of neural networks, such as the Hippie Education or the generated generating networks
Techniques for separating blind signal
Unsupervised learning allows us to address problems that have no idea of our results. We can derive data structures where we do not necessarily know the effect of variables.
Some concepts you really should know
Neural networks
Are inspired by our biological neurons. ANN (artificial neural network) relies on a set of related units or nodes called artificial neurons, which model neurons freely in the biological brain. Each contact, such as clamps in the biological brain, can transmit a signal from one neuron to another. The artificial neuron receiving the signal can be treated and then referred to additional artificial nerve cells attached to it.
Simply put, the neural network is the person making the decisions. There are an unlimited number of neural network topologies, and some species are most appropriate for some problems. This is beyond the scope of this article.
Compensation for variation in bias, adaptation and over-adaptation
It is owned by a set of predictive models where the less biased models in the parameter estimate have a greater difference in parameter estimates between samples and vice versa.
Bias is an error of erroneous assumptions in the learning algorithm. Extreme bias can lead to loss of algorithm-related relationships between properties and destination outputs (insufficient adaptation). The variation is a sensitivity error for small fluctuations in the training group. The high variance can result in a random noise modeling algorithm .
Book for Machine Studying
